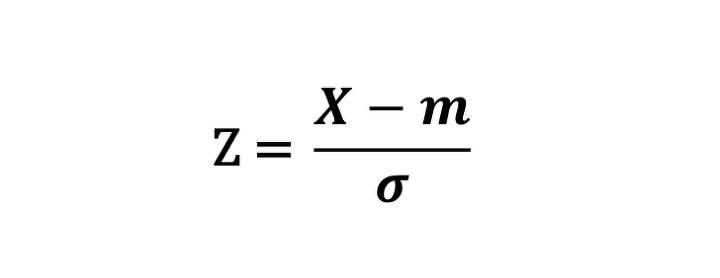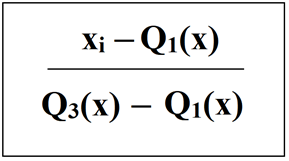특성스케일 조정(Feature scaling)
결정 트리와 랜덤 포레스트(random forest)는 특성 스케일 조정을 걱정할 필요 없지만,
대부분 특성스케일 조정은 매우 중요한 단계이다.
(대부분의 머신 러닝과 최적화 알고리즘은 특성의 스케일이 같을 때 훨씬 성능이 좋다.)
정규화(Normalization)
대부분의 정규화는 특성의 스케일을 [0, 1]로 맞추는 것을 의미한다.
최소-최대 스케일 변환(min-max scaling)의 특별한 경우이다.
MinMaxScaler(최소-최대 스케일 변환)
from sklearn.preprocessing import MinMaxScaler
mms=MinMaxScaler()
X_train_norm=mms.fit_transform(X_train)
X_test_norm=mms.transform(X_test)
표준화(Standardization)
표준화는 머신 러닝 알고리즘(특히 경사 하강법 같은 최적화 알고리즘)에서 널리 사용된다.
가중치를 0또는 0에 가까운 난수로 초기화한다. 표준화를 이용하면 특성의 평균을 0으로 맞추고
표준 편차를 1로 만들어 정규 분포와 같은 특성을 가지게 만든다.
이는 가중치를 더 쉽게 학습할 수 있도록 한다. 또한, 표준화는 이상치 정보가 유지되기 때문에 제한된 범위로 데이터를 조정하는
최소-최대 스케일 변환에 비해 알고리즘이 이상치에 덜 민감하다.( 최소-최대 스케일 변환은 데이터셋에 비정상적으로 큰 값이나
아주 작은 값이 들어 있을 때, 다른 샘플들은 좁은 구간에 촘촘하게 모이게 만든다.)
표준화와 정규화 변환
ex=np.array([0, 1, 2, 3, 4, 5])
print('표준화:',(ex-ex.mean()/ex.std()))
print('정규화:',(ex-ex.min())/(ex.max()-ex.min()))
표준화: [-1.46385011 -0.46385011 0.53614989 1.53614989 2.53614989 3.53614989]
정규화: [0. 0.2 0.4 0.6 0.8 1. ]
StandardScaler(표준화)
from sklearn.preprocessing import StandardScaler
stdsc=StandardScaler()
X_train_std=stdsc.fit_transform(X_train)
X_test_std=stdsc.transform(X_test)
MinMaxScaler와 StandardScaler 모두 fit 매서드는 한번만 적용해야 한다.
RobustScalerrobustsclaer는 이상치가 많이 포함된 작은 데이터셋을 다룰 때 좋다.
또한 알고리즘이 과대적합하기 쉽다면, RobustScaler를 사용하기 좋다.
RobustScaler는 특성 열마다 독립적으로 작용하여 중간 값을 뺀 다음 데이터셋의 1사분위수와 3사분위수(25백분위수, 75백분위수)
를 사용해서 데이터 셋의 스케일을 조정한다. (극단적인 값과 이상치에 영향을 덜 받는다.)
RobustScaler
from sklearn.preprocessing import RobustScaler
rbs=RobustScaler()
X_train_robust=rbs.fit_transform(X_train)
X_test_robust=rbs.fit_transform(X_test)
numpy를 이용해서 변환
(ex-np.percentile(ex, 50))/(np.percentile(ex, 75)-np.percentile(ex, 25))
array([-1. , -0.6, -0.2, 0.2, 0.6, 1. ])
MaxAbsScaler
각 특성별로 데이터를 최대 절댓값으로 나눈다.(각 특성의 최대값은 1이 된다.)
전체 특성은 [-1. 1] 범위로 변경된다.
from sklearn.preprocessing import MaxAbsScaler
mas=MaxAbsScaler()
X_train_maxabs=mas.fit_transform(X_train)
X_test_maxabs=mas.fit_transform(X_test)
numpy를 이용해서 변환
array([0. , 0.2, 0.4, 0.6, 0.8, 1. ])
scale(), minmax_scale(), robust_scale(), maxabs_scale()
위의 함수들을 통해서 1차원 배열도 입력 받을 수 있다.
from sklearn.preprocessing import scale, minmax_scale, robust_scale, maxabs_scale
print('StandardScaler:',scale(ex))
print('MinMaxScaler:',minmax_scale(ex))
print('RobustScaler:',robust_scale(ex))
print('MaxAbsScaler:',maxabs_scale(ex))
StandardScaler: [-1.46385011 -0.87831007 -0.29277002 0.29277002 0.87831007 1.46385011]
MinMaxScaler: [0. 0.2 0.4 0.6 0.8 1. ]
RobustScaler: [-1. -0.6 -0.2 0.2 0.6 1. ]
MaxAbsScaler: [0. 0.2 0.4 0.6 0.8 1. ]
희소 행렬(sparse matrix) ; 대부분의 행렬 값이 0인 행렬
MaxAbsScaler는 데이터를 중앙에 맞추지 않기 때문에 희소 행렬을 사용할 수 있다.
from scipy import sparse
X_train_sparse=sparse.csr_matrix(X_train)
X_train_maxabs=mas.fit_transform(X_train_sparse)
RobustScaler는 fit() 메서드에 희소 행렬을 사용할 수 없지만, transform() 메서드에서 변환은 가능하다.
X_train_robust=rbs.transform(X_train_sparse)
StandardScaler는 width_mean=False 로 지정하면 희소 행렬을 사용할 수 있다.
Normalizer & normalize()
특성이 아니라 샘플별로 정규화를 수행한다. 또한 희소 행렬도 처리할 수 있다.
(기본적으로 각 샘플의 L2 노름이 1이 되도록 정규화)
from sklearn.preprocessing import Normalizer
nrm=Normalizer()
X_train_l2=nrm.fit_transform(X_train)
Normalizer()의 매개변수 norm을 이용해서 노름을 지정할 수 있다.
‘l1’, ‘l2’, ‘max’가 있으며, default값은 ‘l1’ 이다.
numpy를 이용해서 변환
ex_2f=np.vstack((ex[1:], ex[1:]**2))
l2_norm=np.sqrt(np.sum(ex_2f**2, axis=1))
ex_2f/l2_norm.reshape(-1, 1)
array([[0.13483997, 0.26967994, 0.40451992, 0.53935989, 0.67419986],
[0.03196014, 0.12784055, 0.28764125, 0.51136222, 0.79900347]])
norm=‘l1’으로 지정하면 L1노름을 사용한다.
numpy를 이용해서 변환
l1_norm=np.sum(np.abs(ex_2f), axis=1)
ex_2f/l1_norm.reshape(-1, 1)
array([[0.06666667, 0.13333333, 0.2 , 0.26666667, 0.33333333],
[0.01818182, 0.07272727, 0.16363636, 0.29090909, 0.45454545]])
norm=‘max’으로 지정하면 각 샘플의 최대 절댓값을 사용하여 나눈다.
max_norm=np.max(np.abs(ex_2f), axis=1)
ex_2f/max_norm.reshape(-1, 1)
array([[0.2 , 0.4 , 0.6 , 0.8 , 1. ],
[0.04, 0.16, 0.36, 0.64, 1. ]])